Was wir beim Aufbau von KI-Copiloten gelernt haben

Von Hasna Najmi / Senior AI Solutions Architect
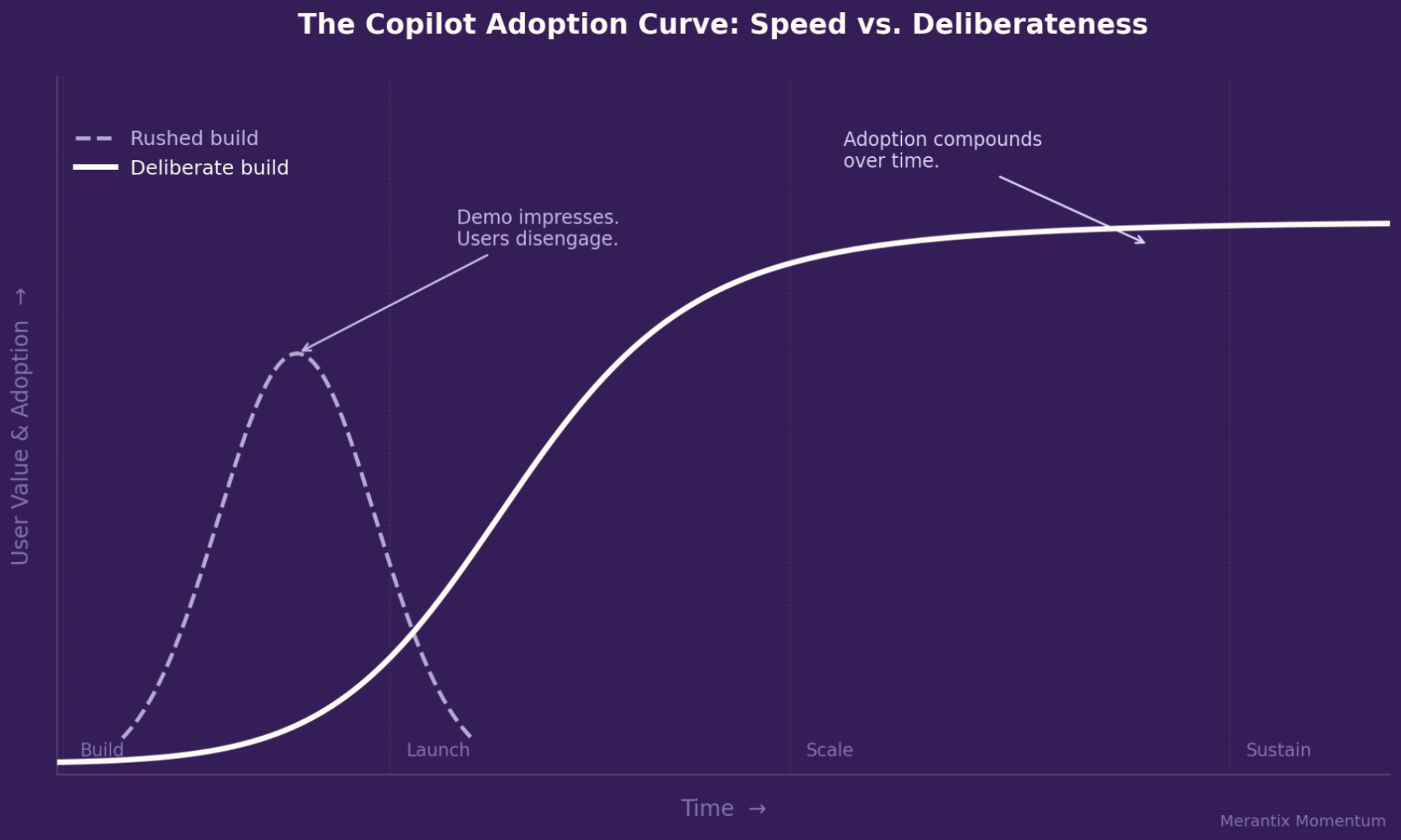
Die Lücke zwischen einem Copiloten, der in der Demo überzeugt, und einem, der die tatsächliche Arbeitsweise von Menschen verändert, ist größer, als viele Teams erwarten.
Jede Woche kündigt ein weiteres Unternehmen an, einen KI Copiloten gebaut zu haben. Eine überzeugende Demo, eine positive interne Kommunikation – und dann oft: stille Unterauslastung sechs Monate später.
Wir haben in den letzten drei Jahren Copilot Systeme in einigen der anspruchsvollsten Umgebungen aufgebaut: große Organisationen im öffentlichen Sektor, spezialisierte juristische Kontexte, Enterprise Workflows mit Tausenden täglichen Nutzern. Wir haben gesehen, was funktioniert. Und wir haben gesehen, was scheitert. Auffällig ist: Die Gründe für das Scheitern ähneln sich stark.
Folgendes sollte jedes Team wissen, bevor es einen Copiloten baut.
Die Retrieval Schicht ist der Punkt, an dem Copiloten am häufigsten scheitern
Es gibt eine Version eines Copiloten, die jeder kennt: Er klingt überzeugend, antwortet flüssig , und liegt gerade oft genug falsch, dass man ihm nicht mehr vertraut. Die Ursache ist fast immer das Retrieval.
Die meisten Enterprise Copiloten basieren auf Dokumenten. Sie ziehen Kontext aus internen Wissensdatenbanken, Richtlinien, Handbüchern oder Datenbanken, bevor sie Antworten generieren. Die Qualität der gefundenen Inhalte setzt die Obergrenze für die Qualität jeder Antwort.
Generische Retrieval Pipelines, die für allgemeine Texte gebaut sind, funktionieren in spezialisierten Domänen oft nicht zuverlässig.
Juristische Sprache funktioniert anders als Alltagssprache. Klinische Terminologie ebenso. Oder die Abkürzungen und Logiken in technischen Spezifikationen. Wenn das Retrieval nicht berücksichtigt, wie Fachexperten tatsächlich Fragen stellen, werden systematisch die falschen Inhalte gezogen und das mit hoher Sicherheit.
Das ist einer der wirkungsvollsten Hebel früh im Aufbau eines Copiloten. Und gleichzeitig einer der am häufigsten unterschätzten.
Ihre Power User sind nicht Ihre einzigen Nutzer
Es ist verlockend, einen Copiloten für die Nutzer zu bauen, die am meisten Interesse daran haben die Early Adopter, die sich mit KI auskennen, kreative Prompts schreiben und das System ausreizen.
Sie liefern wertvolles Feedback. Aber sie repräsentieren nicht die Organisation.
Diejenigen, die am meisten von einem guten Copiloten profitieren würden, sind oft die, die sich am wenigsten sicher im Umgang damit fühlen. Wenn der einzige Einstieg eine leere Texteingabe ohne Orientierung ist, steigen genau diese Nutzer sofort aus und die Nutzung erholt sich nicht mehr.
Copiloten, die sich organisationsweit durchsetzen, bieten mehrere Einstiegspunkte:
Eine offene Interaktion für erfahrene Nutzer. Und strukturierte, geführte Optionen für alle anderen.
Das wirkt wie eine kleine UX Entscheidung. Der Effekt auf die Adoption ist enorm.
Was man nicht messen kann, kann man nicht verbessern
Ein Szenario, das zu häufig vorkommt: Ein Team baut einen Copiloten, testet ihn intern, rollt ihn aus und hat danach keine systematische Möglichkeit zu bewerten, ob er wirklich funktioniert.
Sechs Monate später stellt jemand die Frage: „Ist das Ding eigentlich gut?”
Und niemand kann sie beantworten.
Evaluation muss vor dem Bau definiert werden, nicht danach. Das bedeutet:
- Klar definieren, was „gut“ im konkreten Use Case bedeutet
- Reale Nutzerdaten für Tests sammeln
- Monitoring integrieren, um Qualitätsveränderungen zu erkennen
Synthetische Benchmarks haben ihren Platz. Aber sie zeigen nicht die Probleme, die echte Nutzer finden.
Menschen stellen Fragen auf unerwartete Weise. Sie testen Grenzfälle. Sie nutzen Systeme anders als vorgesehen. Genau das muss sichtbar sein.
Governance ist kein juristisches Problem. Es ist ein Architekturproblem.
Gerade in regulierten Branchen wird Governance oft ans Ende gestellt: eine rechtliche Prüfung, ein paar Richtlinien, ein finales Go.
So funktioniert es nicht.
Datenschutz, Nachvollziehbarkeit und regulatorische Anforderungen – einschließlich des EU AI Acts – müssen von Anfang an Teil der Systemarchitektur sein. Nachträgliches Einbauen ist aufwendig, teuer und selten vollständig.
Und noch wichtiger:
Ein Copilot, der in einem kritischen Kontext selbstbewusst falsche Antworten liefert, erzeugt nicht nur ein Problem im Moment – er zerstört Vertrauen.
Und verlorenes Vertrauen lässt sich nur schwer wieder aufbauen.
Die wichtigste Kennzahl ist Zeit
Retrieval Scores, Benchmarks, Evaluationsmetriken – sie sind wichtig für den Bau.
Aber sie entscheiden nicht darüber, ob ein Copilot langfristig genutzt wird.
Entscheidend ist:
Bekommen die Nutzer Zeit zurück?
- Wird aus einer 20 Minuten Aufgabe eine 5-Minuten-Aufgabe?
- Werden ungeliebte Tätigkeiten einfacher?
Das ist es, was echte Nutzung, interne Fürsprecher und nachhaltige Investitionen treibt.
Die erfolgreichsten Copiloten sind nicht die, die auf Metriken optimiert wurden.
Sondern solche, deren Teams die realen Arbeitsprozesse tief verstanden haben – und von dort aus rückwärts entwickelt haben.
Geschwindigkeit ist wichtig in der KI Entwicklung. Aber sie entscheidet nicht darüber, ob ein Copilot langfristig erfolgreich ist.
Die erfolgreichen Systeme entstehen bewusst:
mit Fokus auf Retrieval, Evaluation, User Experience und Governance – von Anfang an.
Wir haben diese Lektionen auf die harte Tour gelernt – in realen Produktionssystemen, im großen Maßstab.
Wenn Sie einen Copiloten bauen und über Architektur, Umsetzung oder Skalierung sprechen möchten, kommen Sie gerne auf uns zu.
Merantix Momentum ist ein Applied AI Unternehmen, das Organisationen dabei unterstützt, produktionsreife KI-Systeme zu entwickeln und zu betreiben.
Jetzt beim Merantix Momentum Newsletter anmelden.
Weitere Artikel
.png)
.png)

Vom Engpass zum Durchbruch: Warum KI entscheidend für den Fortschritt in Gesundheitswesen und Pharma ist
.png)
.png)
Was wir beim Aufbau von KI-Copiloten gelernt haben
Von Hasna Najmi / Senior AI Solutions Architect
Die Lücke zwischen einem Copiloten, der in der Demo überzeugt, und einem, der die tatsächliche Arbeitsweise von Menschen verändert, ist größer, als viele Teams erwarten.
Jede Woche kündigt ein weiteres Unternehmen an, einen KI Copiloten gebaut zu haben. Eine überzeugende Demo, eine positive interne Kommunikation – und dann oft: stille Unterauslastung sechs Monate später.
Wir haben in den letzten drei Jahren Copilot Systeme in einigen der anspruchsvollsten Umgebungen aufgebaut: große Organisationen im öffentlichen Sektor, spezialisierte juristische Kontexte, Enterprise Workflows mit Tausenden täglichen Nutzern. Wir haben gesehen, was funktioniert. Und wir haben gesehen, was scheitert. Auffällig ist: Die Gründe für das Scheitern ähneln sich stark.
Folgendes sollte jedes Team wissen, bevor es einen Copiloten baut.
Die Retrieval Schicht ist der Punkt, an dem Copiloten am häufigsten scheitern
Es gibt eine Version eines Copiloten, die jeder kennt: Er klingt überzeugend, antwortet flüssig , und liegt gerade oft genug falsch, dass man ihm nicht mehr vertraut. Die Ursache ist fast immer das Retrieval.
Die meisten Enterprise Copiloten basieren auf Dokumenten. Sie ziehen Kontext aus internen Wissensdatenbanken, Richtlinien, Handbüchern oder Datenbanken, bevor sie Antworten generieren. Die Qualität der gefundenen Inhalte setzt die Obergrenze für die Qualität jeder Antwort.
Generische Retrieval Pipelines, die für allgemeine Texte gebaut sind, funktionieren in spezialisierten Domänen oft nicht zuverlässig.
Juristische Sprache funktioniert anders als Alltagssprache. Klinische Terminologie ebenso. Oder die Abkürzungen und Logiken in technischen Spezifikationen. Wenn das Retrieval nicht berücksichtigt, wie Fachexperten tatsächlich Fragen stellen, werden systematisch die falschen Inhalte gezogen und das mit hoher Sicherheit.
Das ist einer der wirkungsvollsten Hebel früh im Aufbau eines Copiloten. Und gleichzeitig einer der am häufigsten unterschätzten.
Ihre Power User sind nicht Ihre einzigen Nutzer
Es ist verlockend, einen Copiloten für die Nutzer zu bauen, die am meisten Interesse daran haben die Early Adopter, die sich mit KI auskennen, kreative Prompts schreiben und das System ausreizen.
Sie liefern wertvolles Feedback. Aber sie repräsentieren nicht die Organisation.
Diejenigen, die am meisten von einem guten Copiloten profitieren würden, sind oft die, die sich am wenigsten sicher im Umgang damit fühlen. Wenn der einzige Einstieg eine leere Texteingabe ohne Orientierung ist, steigen genau diese Nutzer sofort aus und die Nutzung erholt sich nicht mehr.
Copiloten, die sich organisationsweit durchsetzen, bieten mehrere Einstiegspunkte:
Eine offene Interaktion für erfahrene Nutzer. Und strukturierte, geführte Optionen für alle anderen.
Das wirkt wie eine kleine UX Entscheidung. Der Effekt auf die Adoption ist enorm.
Was man nicht messen kann, kann man nicht verbessern
Ein Szenario, das zu häufig vorkommt: Ein Team baut einen Copiloten, testet ihn intern, rollt ihn aus und hat danach keine systematische Möglichkeit zu bewerten, ob er wirklich funktioniert.
Sechs Monate später stellt jemand die Frage: „Ist das Ding eigentlich gut?”
Und niemand kann sie beantworten.
Evaluation muss vor dem Bau definiert werden, nicht danach. Das bedeutet:
- Klar definieren, was „gut“ im konkreten Use Case bedeutet
- Reale Nutzerdaten für Tests sammeln
- Monitoring integrieren, um Qualitätsveränderungen zu erkennen
Synthetische Benchmarks haben ihren Platz. Aber sie zeigen nicht die Probleme, die echte Nutzer finden.
Menschen stellen Fragen auf unerwartete Weise. Sie testen Grenzfälle. Sie nutzen Systeme anders als vorgesehen. Genau das muss sichtbar sein.
Governance ist kein juristisches Problem. Es ist ein Architekturproblem.
Gerade in regulierten Branchen wird Governance oft ans Ende gestellt: eine rechtliche Prüfung, ein paar Richtlinien, ein finales Go.
So funktioniert es nicht.
Datenschutz, Nachvollziehbarkeit und regulatorische Anforderungen – einschließlich des EU AI Acts – müssen von Anfang an Teil der Systemarchitektur sein. Nachträgliches Einbauen ist aufwendig, teuer und selten vollständig.
Und noch wichtiger:
Ein Copilot, der in einem kritischen Kontext selbstbewusst falsche Antworten liefert, erzeugt nicht nur ein Problem im Moment – er zerstört Vertrauen.
Und verlorenes Vertrauen lässt sich nur schwer wieder aufbauen.
Die wichtigste Kennzahl ist Zeit
Retrieval Scores, Benchmarks, Evaluationsmetriken – sie sind wichtig für den Bau.
Aber sie entscheiden nicht darüber, ob ein Copilot langfristig genutzt wird.
Entscheidend ist:
Bekommen die Nutzer Zeit zurück?
- Wird aus einer 20 Minuten Aufgabe eine 5-Minuten-Aufgabe?
- Werden ungeliebte Tätigkeiten einfacher?
Das ist es, was echte Nutzung, interne Fürsprecher und nachhaltige Investitionen treibt.
Die erfolgreichsten Copiloten sind nicht die, die auf Metriken optimiert wurden.
Sondern solche, deren Teams die realen Arbeitsprozesse tief verstanden haben – und von dort aus rückwärts entwickelt haben.
Geschwindigkeit ist wichtig in der KI Entwicklung. Aber sie entscheidet nicht darüber, ob ein Copilot langfristig erfolgreich ist.
Die erfolgreichen Systeme entstehen bewusst:
mit Fokus auf Retrieval, Evaluation, User Experience und Governance – von Anfang an.
Wir haben diese Lektionen auf die harte Tour gelernt – in realen Produktionssystemen, im großen Maßstab.
Wenn Sie einen Copiloten bauen und über Architektur, Umsetzung oder Skalierung sprechen möchten, kommen Sie gerne auf uns zu.
Merantix Momentum ist ein Applied AI Unternehmen, das Organisationen dabei unterstützt, produktionsreife KI-Systeme zu entwickeln und zu betreiben.
.png)
.png)

