Wenn Biologie KI besser macht: Was uns die Vorhersage von Proteinfunktionen über hierarchische Daten gelehrt hat
.png)
Von Glenn Kroegel, Senior Machine Learning Engineer
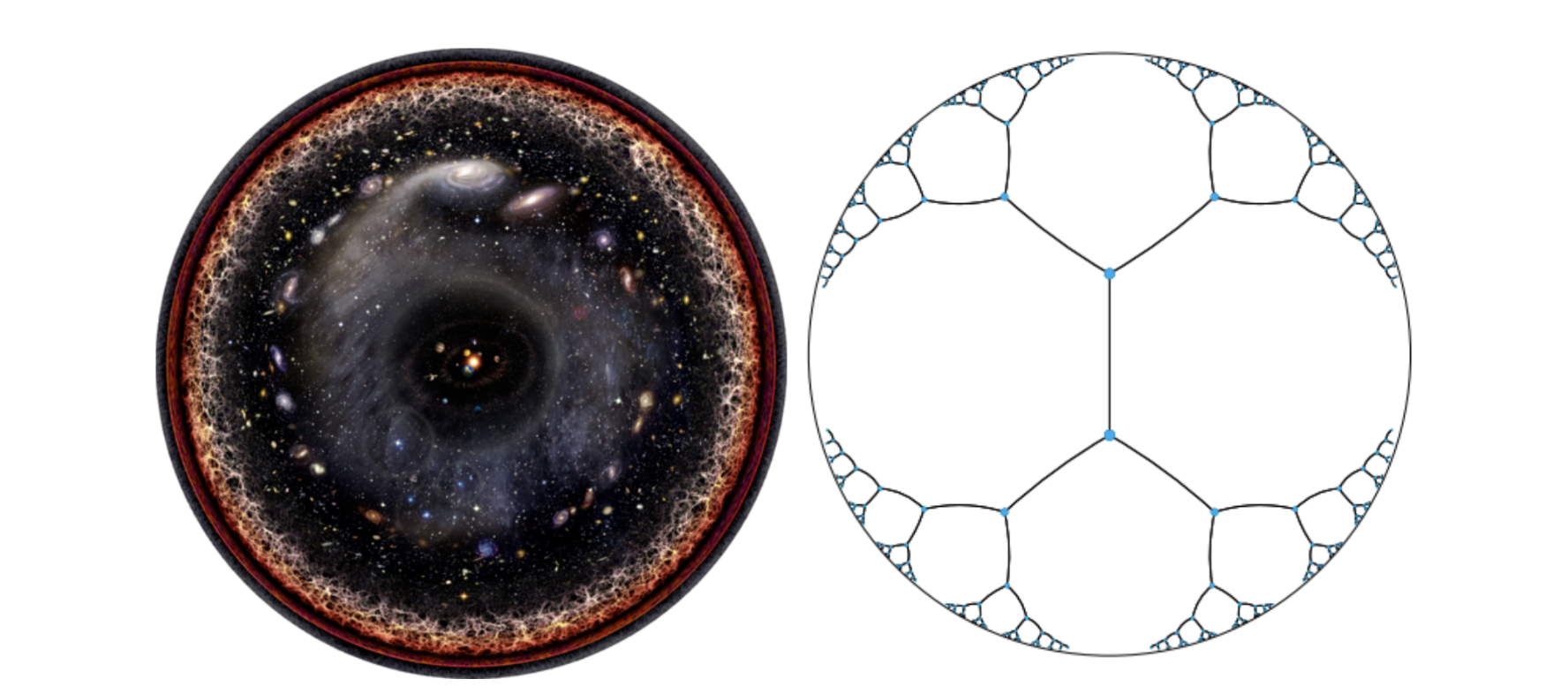
Wie passt das gesamte beobachtbare Universum auf eine einzige Seite? Man platziert unser Sonnensystem in der Mitte und lässt jeden Ring nach außen hin exponentiell größer werden, und schon lässt sich der gesamte Kosmos in eine endliche Scheibe pressen, wie in der Abbildung oben zu sehen. Das ist hyperbolische Geometrie: ein Raum, in dem jeder Schritt vom Zentrum weg exponentiell mehr Platz schafft. Mathematiker haben diese Idee im Poincaré-Ball formalisiert, der oben abgebildet ist.
Wenn diese Geometrie das gesamte Universum auf eine Seite bringen kann, kann sie alles abbilden. Auch einen der komplexesten hierarchischen Datensätze der Biologie, der Proteinfunktionen beschreibt, viele Ebenen tief organisiert, wobei jeder Begriff seine Bedeutung von seinen übergeordneten Begriffen erbt. Inspiriert von der CAFA-6 (Critical Assessment of Functional Annotation) [3] Kaggle-Challenge, bei der es darum geht, Gene-Ontology-Terme (GO-Terme) aus rohen Proteinsequenzen vorherzusagen, möchten wir erklären, was dieses Problem so komplex macht. Der zentrale Komplexitätstreiber ist die Natur der Gene Ontology selbst. GO ist das standardisierte Nachschlagewerk der Wissenschaft für Proteinfunktionen, ein gerichteter azyklischer Graph mit über 45.000 Begriffen, der über Jahrzehnte aufgebaut wurde, um biologisches Wissen einheitlich zu erfassen. Seine Struktur macht Standard-ML aus vier Gründen ungeeignet:
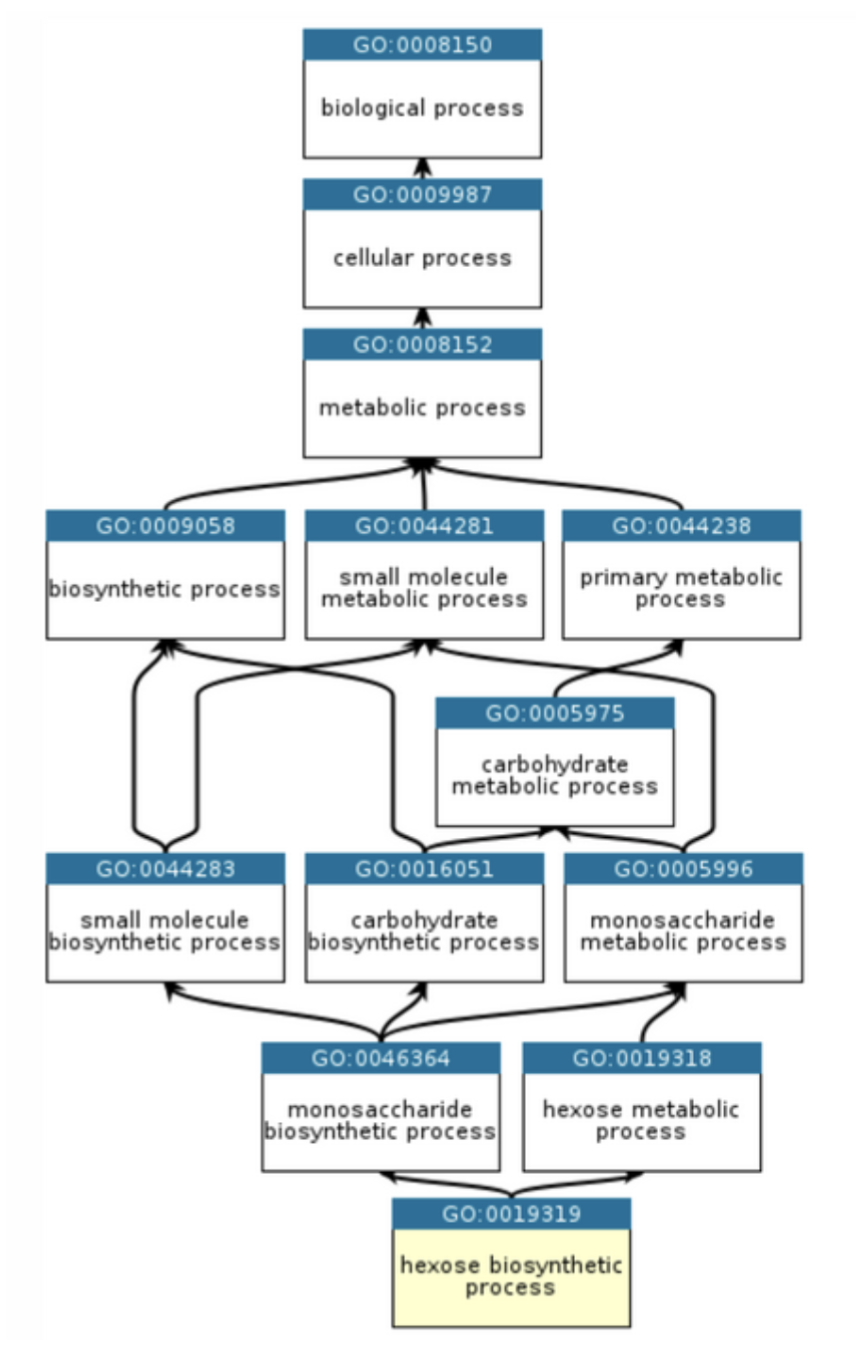
- Erstens ist GO hierarchisch mit transitiver Hülle. Wenn man einen spezifischen Begriff wie „Serin-Typ-Endopeptidase-Aktivität" vorhersagt, behauptet man damit implizit, dass alle übergeordneten Begriffe ebenfalls zutreffen. Ein Modell, das den untersten Begriff richtig vorhersagt, aber die übergeordneten falsch, ist logisch widersprüchlich.
- Zweitens führen über 45.000 Begriffe, bei denen die meisten Proteine nur mit einer Handvoll davon beschriftet sind, zu einem extremen Ungleichgewicht in den Trainingsdaten.
- Drittens, und das ist der subtilste Punkt: Ein fehlendes Label bedeutet kein Negativ. Wenn ein Protein für einen bestimmten Begriff keine Annotation hat, kann das bedeuten, dass der entsprechende Versuch noch nie durchgeführt wurde und nicht, dass die Funktion fehlt.
- Viertens sind die Labels dynamisch. Neue GO-Terme entstehen, wenn die Wissenschaft voranschreitet. Man passt keine feste Verteilung an, sondern versucht, zukünftige wissenschaftliche Entdeckungen vorherzusagen.
Die erste Annahme, die wir aufgeben mussten, war der euklidische Raum. Flache Geometrie wächst nur polynomial, ein Baum, der auf jeder Ebene seine Knoten verdoppelt, läuft schnell aus dem Ruder, Geschwisterknoten werden zusammengequetscht und das hierarchische Signal geht verloren. Mehr Dimensionen helfen zwar, aber man braucht schnell Hunderte davon und kämpft gegen die Geometrie statt mit ihr. Wir sind es gewohnt, einfach mehr Parameter hinzuzufügen aber das gibt uns keine Garantie dafür, dass die ursprüngliche hierarchische Struktur erhalten bleibt.Die Lösung war der oben erwähnte Poincaré-Ball, ein Modell der hyperbolischen Geometrie, in dem der Raum nach außen exponentiell wächst. Der GO-Wurzelknoten sitzt im Zentrum, über 45.000 Blattbegriffe breiten sich zur Grenze hin aus, und das alles in nur 5–10 Dimensionen. Die Geometrie kodiert die Hierarchie von Natur aus. Das ist die zentrale Erkenntnis für die Lösung des Funktionsannotationsproblems.
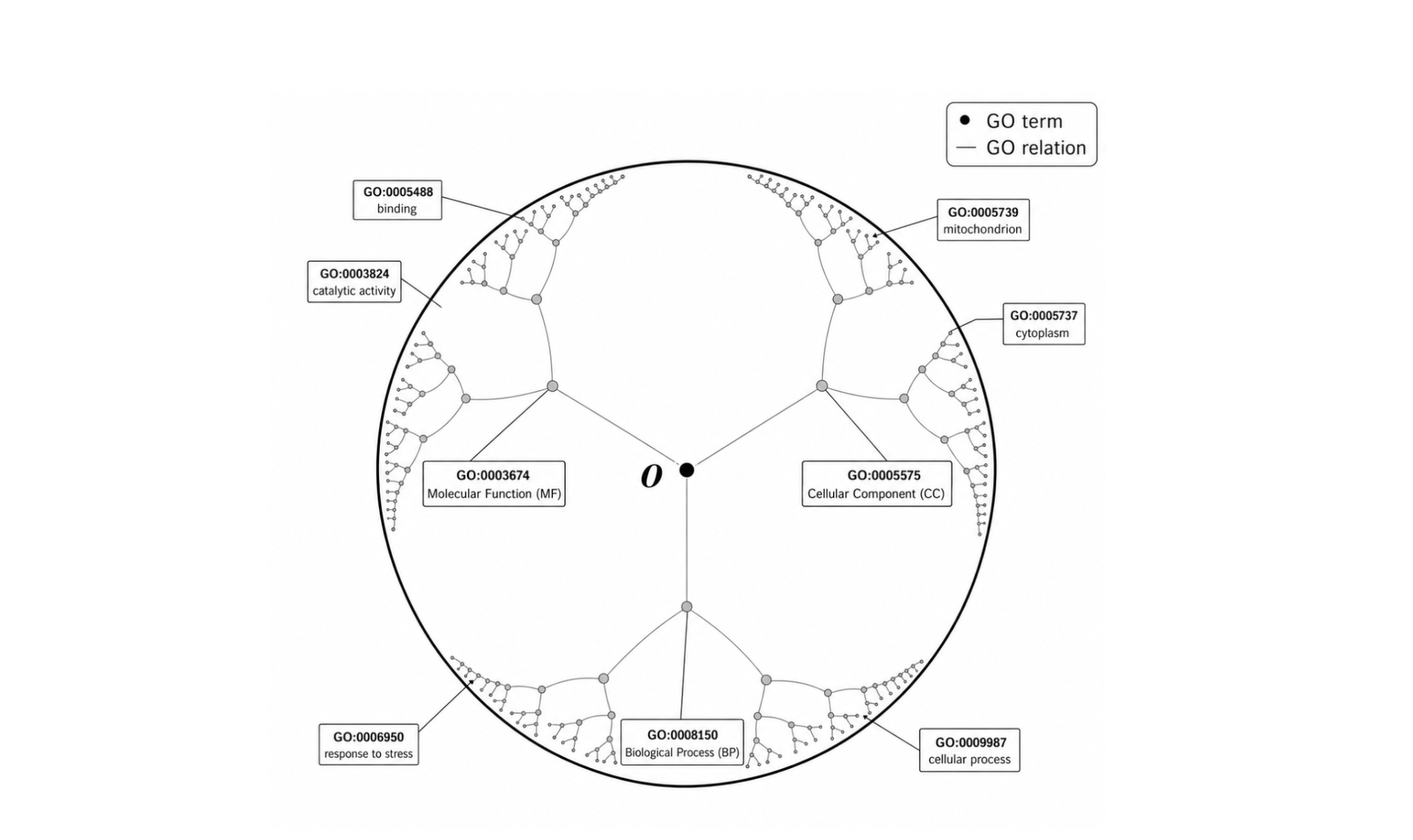
Die GO-Hierarchie in den hyperbolischen Raum einzubetten löst das Darstellungsproblem, aber ein Raum ist nur nützlich, wenn man was darin platzieren kann. Wie kodiert man also ein Protein so, dass seine Position im Poincaré-Ball tatsächlich seine Funktion widerspiegelt? Dafür nutzen wir drei ergänzende Signale: die 3D-Struktur des Proteins, seine evolutionäre Konservierung über Arten hinweg und den biologischen Kontext seiner nächsten Verwandten. Diese drei Signale werden zusammengeführt und über ontologiespezifische Köpfe in den Poincaré-Ball abgebildet. Und hier kommen wir zum dritten Problem: den fehlenden Labels in den Trainingsdaten.
Ein normaler Klassifikator behandelt jedes fehlende Label als echtes Negativ. In den meisten Bereichen ist das eine vernünftige Annahme. In der Proteomik ist es das nicht. Wenn ein Protein für einen bestimmten GO-Begriff keine Annotation hat, könnte das bedeuten, dass der Versuch noch nie durchgeführt wurde - nicht, dass die Funktion fehlt. Ein Modell dafür zu bestrafen, nicht bestätigte aber möglicherweise wahre GO-Terme vorherzusagen, ist nicht nur ungenau - es ist systematisch falsch. Und es wird schlimmer, je tiefer man in die Ontologie vordringt, wo Annotationen am dünnsten sind. Contrastive Loss umgeht dieses Problem, indem er verändert, woraus das Modell lernt. Statt gegen einen festen Satz von Labels vorherzusagen, zieht er Proteine mit gemeinsamen GO-Termen zusammen und schiebt nicht verwandte auseinander - während er Paare ignoriert, die im Graphen nah beieinander liegen, da Nähe im Graphen Verwandtschaft bedeutet, nicht Widerspruch. Sobald ein Protein gut im hyperbolischen Raum platziert ist, kann seine Funktion einfach durch Messen des Abstands zu nahegelegenen GO-Termen erschlossen werden.
Biologisches Wissen hat uns gezwungen, mit tiefen hierarchischen Strukturen und mehrdeutigen Labels umzugehen. Das sind keine exotischen Eigenschaften der Biologie. In der Fertigung gibt es ähnliche Strukturen - eine Stückliste kann über 10 Ebenen tief reichen, vom Rohmaterial bis zur fertigen Baugruppe. Fehlertaxonomien, Lieferantennetzwerke, Produktkataloge, Compliance-Bäume - all diese teilen dieselbe Grundstruktur wie GO, und die meisten werden derzeit in flache Einbettungen gezwungen, die das hierarchische Signal verlieren.
Biologische Datenprobleme sind strukturell oft identisch mit Datenproblemen in anderen Bereichen. Sie sehen nur anders aus und werden von Menschen untersucht, die selten mit den Ingenieuren sprechen, die Fertigungssysteme bauen. Diese Blogserie soll diese Verbindungen sichtbar machen.
Wenn Sie an hierarchischem Representation Learning arbeiten oder im Bereich der Molekularbiologie tätig sind, melden Sie sich gerne bei uns oder besuchen Sie uns auf dem AI Campus in Berlin!
Quelle
(1) Observable universe logarithmic illustration von Pablo Carlos Budassi, erstellt für Wikipedia.org. Verfügbar unter: https://commons.wikimedia.org/wiki/File:Observable_universe_logarithmic_illustration.png
(2) Nickel, Maximillian, und Douwe Kiela. „Poincaré embeddings for learning hierarchical representations." Advances in neural information processing systems 30 (2017).
(3) https://www.kaggle.com/competitions/cafa-6-protein-function-prediction
(4) https://geneontology.org/docs/ontology-documentation/
Jetzt beim Merantix Momentum Newsletter anmelden.
Weitere Artikel
.png)
%20(1).png)

.png)

Vom Engpass zum Durchbruch: Warum KI entscheidend für den Fortschritt in Gesundheitswesen und Pharma ist
Wenn Biologie KI besser macht: Was uns die Vorhersage von Proteinfunktionen über hierarchische Daten gelehrt hat
Von Glenn Kroegel, Senior Machine Learning Engineer
Wie passt das gesamte beobachtbare Universum auf eine einzige Seite? Man platziert unser Sonnensystem in der Mitte und lässt jeden Ring nach außen hin exponentiell größer werden, und schon lässt sich der gesamte Kosmos in eine endliche Scheibe pressen, wie in der Abbildung oben zu sehen. Das ist hyperbolische Geometrie: ein Raum, in dem jeder Schritt vom Zentrum weg exponentiell mehr Platz schafft. Mathematiker haben diese Idee im Poincaré-Ball formalisiert, der oben abgebildet ist.
Wenn diese Geometrie das gesamte Universum auf eine Seite bringen kann, kann sie alles abbilden. Auch einen der komplexesten hierarchischen Datensätze der Biologie, der Proteinfunktionen beschreibt, viele Ebenen tief organisiert, wobei jeder Begriff seine Bedeutung von seinen übergeordneten Begriffen erbt. Inspiriert von der CAFA-6 (Critical Assessment of Functional Annotation) [3] Kaggle-Challenge, bei der es darum geht, Gene-Ontology-Terme (GO-Terme) aus rohen Proteinsequenzen vorherzusagen, möchten wir erklären, was dieses Problem so komplex macht. Der zentrale Komplexitätstreiber ist die Natur der Gene Ontology selbst. GO ist das standardisierte Nachschlagewerk der Wissenschaft für Proteinfunktionen, ein gerichteter azyklischer Graph mit über 45.000 Begriffen, der über Jahrzehnte aufgebaut wurde, um biologisches Wissen einheitlich zu erfassen. Seine Struktur macht Standard-ML aus vier Gründen ungeeignet:
- Erstens ist GO hierarchisch mit transitiver Hülle. Wenn man einen spezifischen Begriff wie „Serin-Typ-Endopeptidase-Aktivität" vorhersagt, behauptet man damit implizit, dass alle übergeordneten Begriffe ebenfalls zutreffen. Ein Modell, das den untersten Begriff richtig vorhersagt, aber die übergeordneten falsch, ist logisch widersprüchlich.
- Zweitens führen über 45.000 Begriffe, bei denen die meisten Proteine nur mit einer Handvoll davon beschriftet sind, zu einem extremen Ungleichgewicht in den Trainingsdaten.
- Drittens, und das ist der subtilste Punkt: Ein fehlendes Label bedeutet kein Negativ. Wenn ein Protein für einen bestimmten Begriff keine Annotation hat, kann das bedeuten, dass der entsprechende Versuch noch nie durchgeführt wurde und nicht, dass die Funktion fehlt.
- Viertens sind die Labels dynamisch. Neue GO-Terme entstehen, wenn die Wissenschaft voranschreitet. Man passt keine feste Verteilung an, sondern versucht, zukünftige wissenschaftliche Entdeckungen vorherzusagen.
Die erste Annahme, die wir aufgeben mussten, war der euklidische Raum. Flache Geometrie wächst nur polynomial, ein Baum, der auf jeder Ebene seine Knoten verdoppelt, läuft schnell aus dem Ruder, Geschwisterknoten werden zusammengequetscht und das hierarchische Signal geht verloren. Mehr Dimensionen helfen zwar, aber man braucht schnell Hunderte davon und kämpft gegen die Geometrie statt mit ihr. Wir sind es gewohnt, einfach mehr Parameter hinzuzufügen aber das gibt uns keine Garantie dafür, dass die ursprüngliche hierarchische Struktur erhalten bleibt.Die Lösung war der oben erwähnte Poincaré-Ball, ein Modell der hyperbolischen Geometrie, in dem der Raum nach außen exponentiell wächst. Der GO-Wurzelknoten sitzt im Zentrum, über 45.000 Blattbegriffe breiten sich zur Grenze hin aus, und das alles in nur 5–10 Dimensionen. Die Geometrie kodiert die Hierarchie von Natur aus. Das ist die zentrale Erkenntnis für die Lösung des Funktionsannotationsproblems.
Die GO-Hierarchie in den hyperbolischen Raum einzubetten löst das Darstellungsproblem, aber ein Raum ist nur nützlich, wenn man was darin platzieren kann. Wie kodiert man also ein Protein so, dass seine Position im Poincaré-Ball tatsächlich seine Funktion widerspiegelt? Dafür nutzen wir drei ergänzende Signale: die 3D-Struktur des Proteins, seine evolutionäre Konservierung über Arten hinweg und den biologischen Kontext seiner nächsten Verwandten. Diese drei Signale werden zusammengeführt und über ontologiespezifische Köpfe in den Poincaré-Ball abgebildet. Und hier kommen wir zum dritten Problem: den fehlenden Labels in den Trainingsdaten.
Ein normaler Klassifikator behandelt jedes fehlende Label als echtes Negativ. In den meisten Bereichen ist das eine vernünftige Annahme. In der Proteomik ist es das nicht. Wenn ein Protein für einen bestimmten GO-Begriff keine Annotation hat, könnte das bedeuten, dass der Versuch noch nie durchgeführt wurde - nicht, dass die Funktion fehlt. Ein Modell dafür zu bestrafen, nicht bestätigte aber möglicherweise wahre GO-Terme vorherzusagen, ist nicht nur ungenau - es ist systematisch falsch. Und es wird schlimmer, je tiefer man in die Ontologie vordringt, wo Annotationen am dünnsten sind. Contrastive Loss umgeht dieses Problem, indem er verändert, woraus das Modell lernt. Statt gegen einen festen Satz von Labels vorherzusagen, zieht er Proteine mit gemeinsamen GO-Termen zusammen und schiebt nicht verwandte auseinander - während er Paare ignoriert, die im Graphen nah beieinander liegen, da Nähe im Graphen Verwandtschaft bedeutet, nicht Widerspruch. Sobald ein Protein gut im hyperbolischen Raum platziert ist, kann seine Funktion einfach durch Messen des Abstands zu nahegelegenen GO-Termen erschlossen werden.
Biologisches Wissen hat uns gezwungen, mit tiefen hierarchischen Strukturen und mehrdeutigen Labels umzugehen. Das sind keine exotischen Eigenschaften der Biologie. In der Fertigung gibt es ähnliche Strukturen - eine Stückliste kann über 10 Ebenen tief reichen, vom Rohmaterial bis zur fertigen Baugruppe. Fehlertaxonomien, Lieferantennetzwerke, Produktkataloge, Compliance-Bäume - all diese teilen dieselbe Grundstruktur wie GO, und die meisten werden derzeit in flache Einbettungen gezwungen, die das hierarchische Signal verlieren.
Biologische Datenprobleme sind strukturell oft identisch mit Datenproblemen in anderen Bereichen. Sie sehen nur anders aus und werden von Menschen untersucht, die selten mit den Ingenieuren sprechen, die Fertigungssysteme bauen. Diese Blogserie soll diese Verbindungen sichtbar machen.
Wenn Sie an hierarchischem Representation Learning arbeiten oder im Bereich der Molekularbiologie tätig sind, melden Sie sich gerne bei uns oder besuchen Sie uns auf dem AI Campus in Berlin!
Quelle
(1) Observable universe logarithmic illustration von Pablo Carlos Budassi, erstellt für Wikipedia.org. Verfügbar unter: https://commons.wikimedia.org/wiki/File:Observable_universe_logarithmic_illustration.png
(2) Nickel, Maximillian, und Douwe Kiela. „Poincaré embeddings for learning hierarchical representations." Advances in neural information processing systems 30 (2017).
(3) https://www.kaggle.com/competitions/cafa-6-protein-function-prediction
(4) https://geneontology.org/docs/ontology-documentation/
.png)
.png)

{kind=link}